
vstackai-law-1: Best in Class Legal Embedding Model
TL;DR – Our vstackai-law-1 model is redefining legal document retrieval, topping the MTEB legal leaderboard. It significantly outperforms both the widely used OpenAI's text-embedding-3-large and the nearest domain-specific rival, VoyageAI's voyage-law-2. Capable of processing up to 32,000 tokens and supporting multiple languages, vstackai-law-1 handles complex legal texts effortlessly. This model not only improves retrieval accuracy but also establishes a new industry standard by delivering 3x better performance per dollar.
At VectorStack AI, we're dedicated to building foundational components for a Generative AI stack that can be fully optimized end-to-end for specialized industries. In this blog post, we will focus on the legal domain — a field ripe for transformation through Generative AI.
A significant portion of legal work involves sifting through vast repositories of cases, documents, and contracts. This makes it an ideal field for AI-driven optimization. By leveraging GenAI, legal professionals can optimize how they conduct research (case law, precedents, statutes, etc), draft documents, and derive insights from complex legal materials.
Embeddings: The Backbone of Legal AI
Embedding models serve as the foundation of any AI application in legal domain. These models take text data as input and transform it into a sequence of numbers, known as embeddings. A practical example of how embeddings work is illustrated in the figure below. A legal query is processed by the embedding model to generate its corresponding embedding. This embedding is then passed to a vector database, where it is compared with the embeddings of an entire dataset. The document most closely related to the query is subsequently retrieved.
While this example provides a simplified overview of embedding usage, the real-world applications are far-reaching. Embedding models can significantly enhance various legal tasks, such as identifying similar cases, finding relevant precedents, and locating applicable statutes—ultimately streamlining and accelerating legal research and analysis.
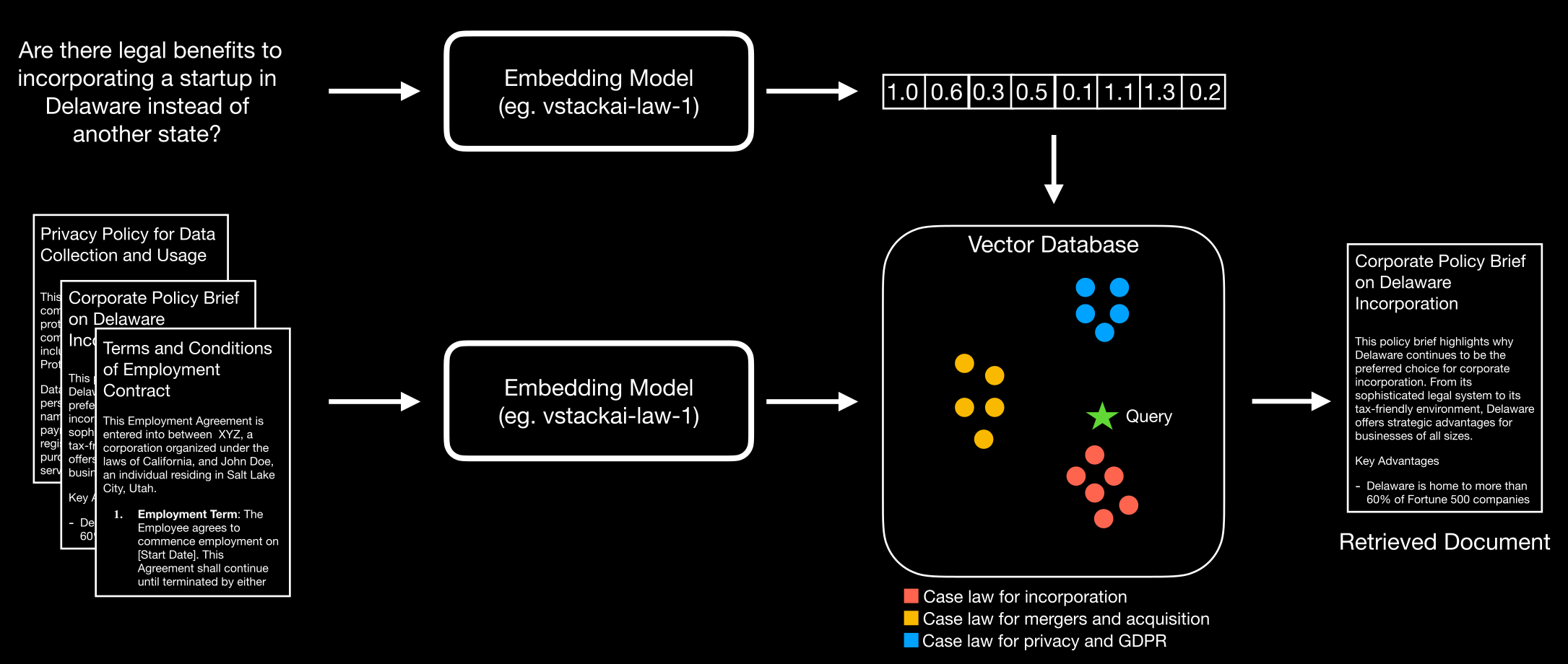
Why generic embedding models fail to do well in legal domain?
Compared to most text domains, the legal domain presents a unique challenges due to its reliance on precise language, nuanced contexts, and specialized terminology. While generic embedding models from providers like OpenAI, Cohere, and Mistral offer broad applicability, they fail to capture the intricate details of legal text with the accuracy required for high-stakes legal applications.
For instance, in the figure below, we compare the top passages retrieved by OpenAI’s text-embedding-3-large model and our vstackai-law-1 model. The passage retrieved by OpenAI’s model is related to the query, as it mentions terms and concepts relevant to the question. However, it does not provide an answer to the query. In contrast, our vstackai-law-1 model demonstrates a deeper understanding of legal precedents, retrieving a precise and contextually accurate passage that directly answers the question.

Best-in-Class Legal Domain Embeddings
To bridge this gap in the legal AI space, we developed vstackai-law-1, a cutting-edge embedding model specifically tailored for the legal domain. Our model has been extensively trained on diverse legal text datasets, leveraging a variety of tasks during the training process. These tasks span a wide range of complexities, languages, and subdomains. For instance, some tasks involve retrieving relevant contracts based on a query, while others focus on identifying legal precedents from case documents. To ensure robustness, we curated a comprehensive and high-quality legal dataset that captures a broad spectrum of real-world use cases.
Our training process employs a legal domain-specific curriculum learning framework paired with a novel metric learning formulation to optimize the model’s performance. The result is an advanced embedding model capable of addressing the nuanced requirements of legal text analysis.
Key features of vstackai-law-1 include:
Multilingual support: The model handles English, major European languages (e.g., German, Dutch, French), and Chinese with ease.
Variable embedding size: By default, embeddings are generated at a size of 1536 dimensions. For users aiming to reduce hosting costs on VectorDB, the model supports binary quantization and variable-length embeddings (inspired by the "Matryoshka" representation).
Extended token limit: While competitor models like voyage-law-2 can process inputs up to 16,000 tokens, vstackai-law-1 accommodates sequences of up to 32,000 tokens. This eliminates the need for document chunking, making it ideal for processing large legal documents in their entirety.

Our model outperforms the competition on all key metrics, including accuracy, latency, cost-efficiency, and maximum sequence length. These advantages are highlighted in the comparison table below, which underscores vstackai-law-1’s superior performance in real-world legal applications.
Quantitative Evaluation on Real World Datasets
-
To ensure our benchmarking is both rigorous and comparable, we evaluated our vstackai-law-1 embedding model on publicly available datasets used in the Massive Text Embedding Benchmark (MTEB) Leaderboard for the legal domain. This leaderboard is a widely recognized standard for assessing embedding model performance, allowing direct comparison with both domain-specific and generic models.
We selected the 8 datasets featured in the legal leaderboard, which span key legal sub-domains such as contracts, Supreme Court cases, statutes, and legal summaries. These datasets cover three languages—English, Chinese, and German—and comprehensively represent diverse legal tasks, ensuring a holistic evaluation of our model’s capabilities.
For consistency with the MTEB leaderboard, we used the NDCG@10 (Normalized Discounted Cumulative Gain) metric. This metric evaluates ranking quality by comparing the produced rankings against an ideal ordering where all relevant items appear at the top. A higher NDCG@10 score reflects better performance in retrieving and ranking relevant information. Learn more about the NDCG metric here. In addition to NDCG@10 metric, we will also evaluate these offerings with a more practical metric: performance/ dollar. Here for performance we used the NDCG@10 metric, and for cost we evaluate the dollar cost of embedding 1 million tokens ($/ 1 M tokens).
The table below presents the performance comparison of vstackai-law-1 with domain-specific competitors (VoyageAI’s voyage-law-2) and leading generic models, such as: OpenAI (text-embedding-3-large), Mistral (mistral-embed), Cohere V3 (embed-english-v3).
The vstackai-law-1 embedding model consistently outperforms competitors, achieving top scores across all datasets. In contrast, the second-best model, voyage-law-2, exhibits significant performance drops on certain challenging datasets, such as LeCardv2 (Chinese) and GerDaLIR (German). These datasets involve embedding large and complex legal cases, highlight the advantages of vstackai-law-1's specialized training on high-quality, domain-specific, and challenging legal data. You can look view the full evaluation on MTEB’s law leaderboard.
In addition to accuracy, the vstackai-law-1 model delivers exceptional cost-efficiency. As shown in the analysis, it achieves approximately 3x higher accuracy per dollar compared to VoyageAI-law. This is a critical advantage for enterprise-scale applications, where embedding millions of tokens is a regular requirement. By combining state-of-the-art performance with low cost per million tokens, vstackai-law-1 enables organizations to achieve top-tier results while significantly reducing operational expenses.

Conclusion and Next Steps
The launch of vstackai-law-1 demonstrates the transformative potential of domain-specific models in legal text analysis, offering unmatched precision, efficiency, and scalability. Beyond its core capabilities, vstackai-law-1 addresses a key challenge for enterprises: the cost and complexity of fine-tuning generic models. Designed for efficient fine-tuning, it enables organizations to achieve state-of-the-art performance quickly and cost-effectively, meeting their unique requirements with ease.
Stay tuned for more updates in an upcoming post. In the meantime, if your organization is interested in exploring our models, providing feedback, or requesting a custom legal embedding model, feel free to contact us at inquiry@vectorstack.ai.