
Optimizing Generative AI
one component at a time end-to-end
From embedding models to vector databases, and more, we’re laying the foundation for a vertically integrated GenAI stack; delivering better quality at a fraction of the cost.
State of the art compression

Reduce memory footprint of embeddings without hurting accuracy; lower storage costs; enable edge deployment
Lower cost of ownership

Reduce the cost of ownership while meeting high level KPIs (accuracy, latency, etc.)
State of the art domain specific models
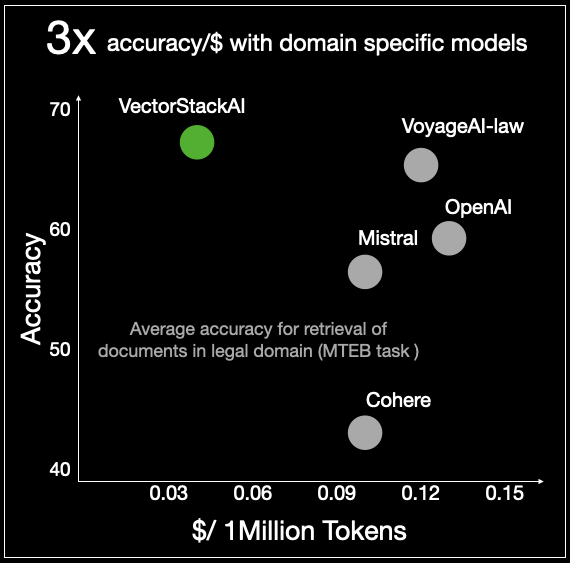
Custom domain specific fine-tuned models; higher accuracy at lower cost. Read the blog post!